什么是 Groq?
最近,Groq (在新标签页中打开) 作为目前最快的 LLM 推理解决方案之一,备受瞩目。LLM 从业者对降低 LLM 响应的延迟表现出极大兴趣。延迟是一个重要的优化指标,可以支持实时 AI 应用。目前,有许多公司正在围绕 LLM 推理展开竞争。
Groq 是众多 LLM 推理公司之一,在撰写本文时,他们声称在 Anyscale 的 LLMPerf 排行榜 (在新标签页中打开) 上的推理性能比其他顶级云服务提供商快 18 倍。Groq 目前通过其 API 提供 Meta AI 的 Llama 2 70B 和 Mixtral 8x7B 等模型。这些模型由 Groq LPU™ 推理引擎提供支持,该引擎采用其专有的、专为运行 LLM 设计的定制硬件构建,称为语言处理单元(LPUs)。
根据 Groq 的常见问题解答,LPU 有助于减少每字计算时间,从而实现更快的文本序列生成。您可以在其荣获 ISCA 奖项的 2020 年 (在新标签页中打开) 和 2022 年 (在新标签页中打开) 论文中阅读更多关于 LPU 的技术细节及其优势。
以下是其模型速度和定价的图表

下表比较了输出 token 吞吐量(tokens/s),即每秒返回的平均输出 token 数。图表中的数字对应于 LLM 推理提供商在 Llama 2 70B 模型上的平均输出 token 吞吐量(基于 150 个请求)。
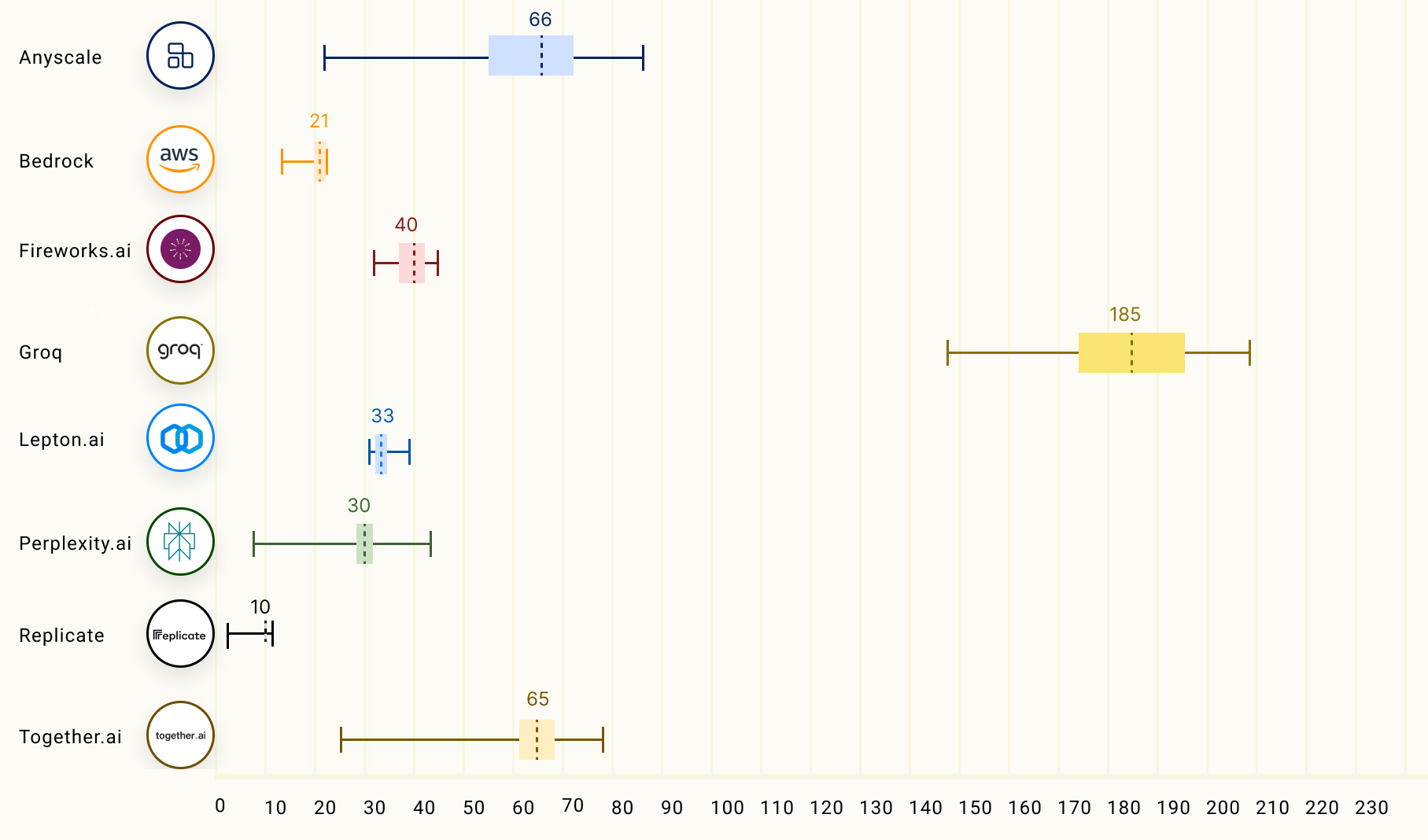
LLM 推理的另一个重要因素,特别是对于流式应用,称为首个 token 生成时间(TTFT),它表示 LLM 返回第一个 token 所需的时间。下表显示了不同 LLM 推理提供商的表现
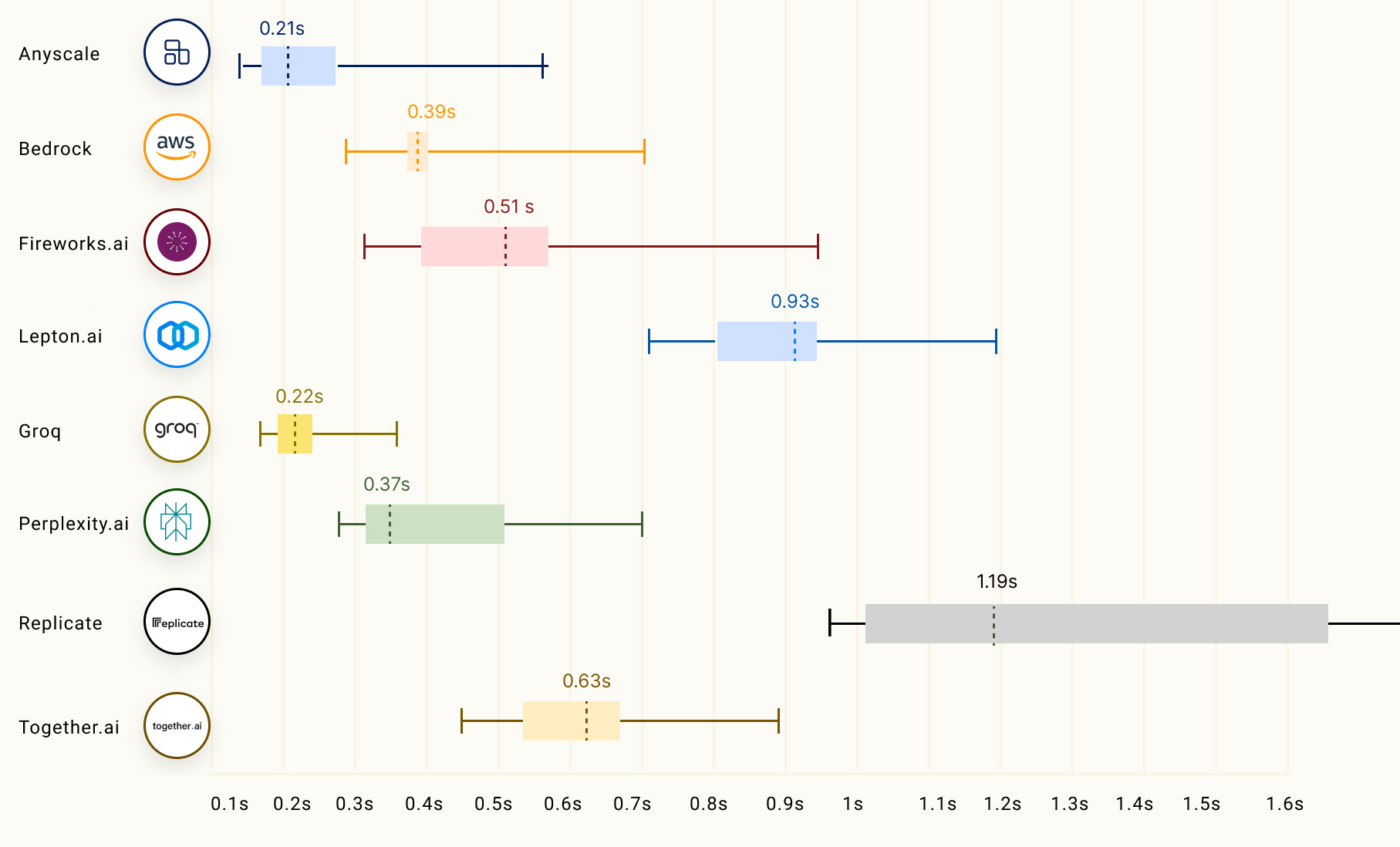
您可以在 此处 (在新标签页中打开) 阅读更多关于 Groq 在 Anyscale 的 LLMPerf 排行榜上的 LLM 推理性能信息。